Quand j’ai commencé à construire un système RAG en Rust pour documenter automatiquement des codebases legacy, la première question de production n’était pas sur le modèle ni sur les embeddings. C’était : où est-ce que je fais tourner ça ?
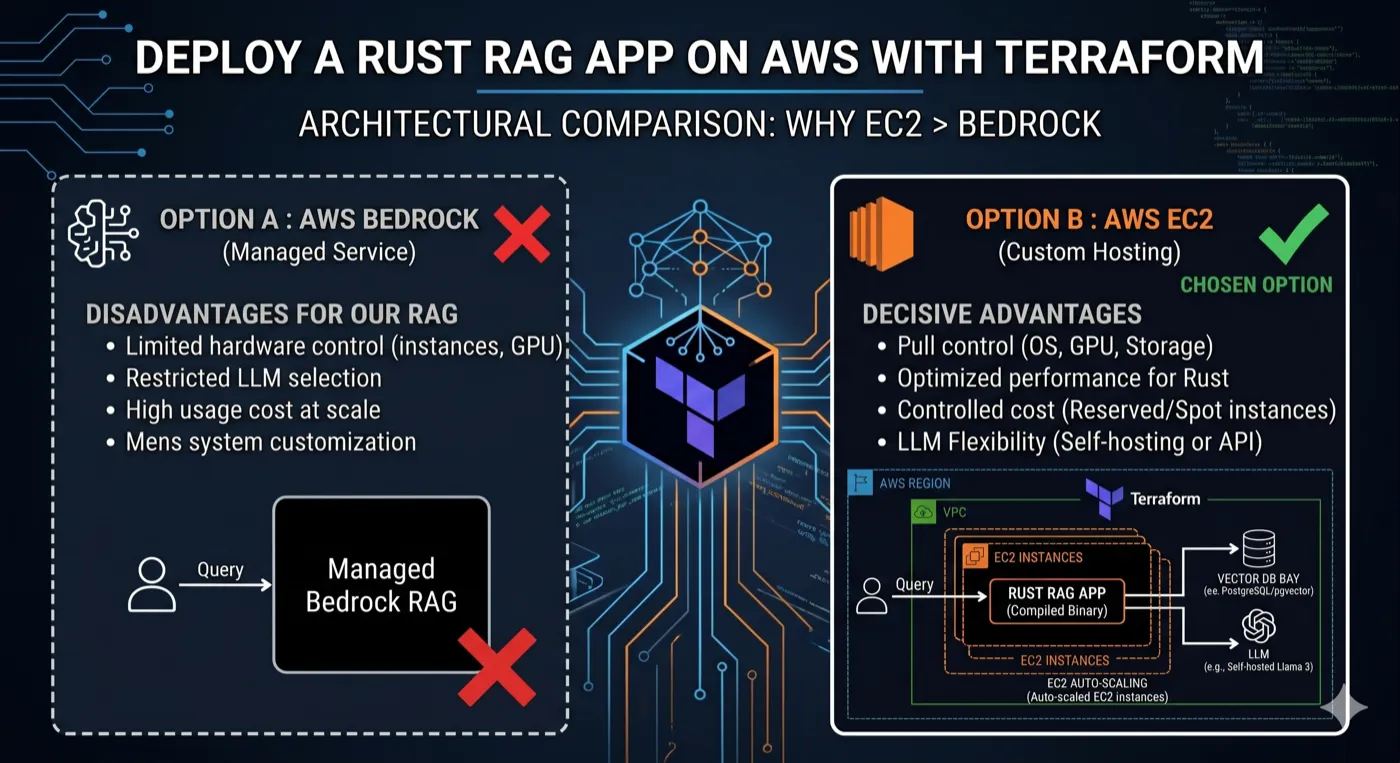
La réponse évidente en 2026, c’est AWS Bedrock. C’est managé, ça scale, et AWS le pousse fort. J’ai choisi EC2. Cet article explique pourquoi, et détaille l’infrastructure Terraform que j’ai construite pour que ça tourne correctement.
Pourquoi pas Bedrock ?
Bedrock est le bon choix pour beaucoup d’équipes. Mais pas pour moi, pour trois raisons.
J’avais besoin de Qdrant. L’application utilise Qdrant comme base de données vectorielle, un moteur de recherche de similarité haute performance écrit en Rust. Le store vectoriel natif de Bedrock, c’est Amazon OpenSearch Serverless ou pgvector. Migrer vers l’un ou l’autre aurait signifié réécrire la logique de requêtes principale et perdre des fonctionnalités dont je dépendais : collections nommées, filtrage de payload, métriques de distance fine.
Je fais tourner un binaire Rust, pas du Python. La plupart des tutos Bedrock supposent LangChain + Python. Mon backend est un binaire Rust compilé. L’overhead d’adapter l’architecture à Lambda (cold starts, taille du binaire, async runtime) ne valait pas le coup pour un outil interne à trafic prévisible.
La prédictibilité des coûts comptait. Bedrock facture au token consommé. Pour un outil qui indexe des codebases Java entières (parfois des millions de tokens par projet), la facturation devient imprévisible. Un EC2 t3.medium à ~30€/mois est plus facile à raisonner.
La stack
Avant d’entrer dans Terraform, voici ce que je déploie :
- Backend : binaire Rust packagé en image Docker, faisant tourner le moteur RAG, l’API HTTP et le serveur MCP
- Frontend : app Angular servie via nginx dans un second conteneur Docker
- Store vectoriel : Qdrant, en conteneur Docker sur la même instance
- Base de données : SQLite pour les métadonnées de projets (pas de RDS, ça garde les coûts bas)
- LLM provider : OpenRouter (appelle Claude, GPT-4, etc. via une seule API)
Tout tourne sur une instance EC2 derrière un Application Load Balancer. Pas de microservices. Pas de Kubernetes. Une instance avec Docker Compose.
L’infrastructure
Voici la vue complète de ce que Terraform provisionne :
Internet
│
▼
ALB (HTTPS:443 / HTTP:80→301)
│
▼
EC2 t3.medium (Amazon Linux 2023)
├── conteneur nginx (port 3000 → frontend)
├── conteneur backend (port 8080 → API Rust)
└── conteneur qdrant (port 6333 → vector DB)
│
▼
Volume EBS gp3 (/data persistant)
├── qdrant_storage/
└── bases SQLiteTous les secrets (clés API LLM, credentials OAuth) vivent dans AWS Secrets Manager et sont injectés dans l’instance EC2 au démarrage via user_data.
Les images sont stockées dans ECR et tirées à chaque déploiement.
Les décisions Terraform clés
Le remote state d’abord
Avant terraform apply, il faut un endroit pour stocker le state. Deux commandes AWS CLI :
aws s3 mb s3://my-app-tfstate --region eu-west-1
aws dynamodb create-table \
--table-name my-app-tflock \
--attribute-definitions AttributeName=LockID,AttributeType=S \
--key-schema AttributeName=LockID,KeyType=HASH \
--billing-mode PAY_PER_REQUEST \
--region eu-west-1Puis l’init avec le backend :
terraform init \
-backend-config="bucket=my-app-tfstate" \
-backend-config="key=prod/terraform.tfstate" \
-backend-config="region=eu-west-1" \
-backend-config="dynamodb_table=my-app-tflock"La table DynamoDB fournit le state locking, ce qui est critique si plusieurs ingénieurs ou pipelines CI exécutent Terraform en parallèle.
Le problème du stateful : Qdrant sur EBS
C’est la décision architecturale la plus importante. Qdrant stocke les collections vectorielles sur disque. Si on laisse Terraform détruire et recréer l’instance EC2 (ce qui arrive lors de mises à jour d’AMI ou de changements de type d’instance), on perd toutes les données indexées. Réindexer une grande codebase prend des heures.
La solution : un volume EBS séparé avec prevent_destroy :
resource "aws_ebs_volume" "data" {
availability_zone = var.availability_zones[0]
size = var.data_volume_size_gb
type = "gp3"
encrypted = true
lifecycle {
prevent_destroy = true
}
}
resource "aws_volume_attachment" "data" {
device_name = "/dev/xvdf"
volume_id = aws_ebs_volume.data.id
instance_id = aws_instance.app.id
force_detach = false
}Le prevent_destroy = true signifie que Terraform refusera d’exécuter tout plan qui supprimerait ce volume. C’est un garde-fou contre un terraform destroy accidentel. Si j’ai vraiment besoin de le supprimer, je retire le bloc lifecycle, j’applique, puis je détruis.
Sur l’instance, /data est monté depuis ce volume au démarrage via user_data. Les bases SQLite et les collections Qdrant vivent toutes là. L’instance est remplaçable ; le volume de données ne l’est pas.
J’ai aussi mis en place des sauvegardes AWS Backup quotidiennes :
resource "aws_backup_plan" "daily" {
name = "${local.prefix}-backup-daily"
rule {
rule_name = "daily-7days"
target_vault_name = aws_backup_vault.main.name
schedule = "cron(0 2 * * ? *)"
lifecycle {
delete_after = 7
}
}
}Sept jours de snapshots quotidiens. Si quelque chose corrompt le storage Qdrant, je restaure depuis la sauvegarde de la nuit précédente.
Secrets Manager pour les clés LLM
Ne jamais mettre des clés API dans terraform.tfvars ou dans des variables d’environnement dans user_data. J’utilise Secrets Manager :
resource "aws_secretsmanager_secret" "openrouter_api_key" {
name = "${local.prefix}/openrouter-api-key"
recovery_window_in_days = 7
}
resource "aws_secretsmanager_secret_version" "openrouter_api_key" {
secret_id = aws_secretsmanager_secret.openrouter_api_key.id
secret_string = "PLACEHOLDER_SET_ME"
lifecycle {
ignore_changes = [secret_string]
}
}Le ignore_changes = [secret_string] est essentiel : Terraform crée le secret avec un placeholder, puis je mets la vraie valeur via CLI. Les terraform apply suivants n’écraseront pas ce que j’ai défini manuellement.
aws secretsmanager put-secret-value \
--secret-id arn:aws:secretsmanager:eu-west-1:...:secret:prod/openrouter-api-key \
--secret-string "sk-or-v1-..."L’instance EC2 a un rôle IAM avec la permission de lire ces secrets. Le user_data les récupère au démarrage et les injecte comme variables d’environnement dans le stack Docker Compose.
ALB avec TLS automatique
L’ALB gère la terminaison TLS. Si je fournis un domain_name et un zone_id Route 53, Terraform crée et valide automatiquement un certificat ACM :
resource "aws_acm_certificate" "main" {
count = local.has_domain ? 1 : 0
domain_name = var.domain_name
validation_method = "DNS"
lifecycle {
create_before_destroy = true
}
}Le HTTP sur le port 80 redirige vers HTTPS avec un 301. La politique TLS est ELBSecurityPolicy-TLS13-1-2-2021-06, qui impose TLS 1.3 et 1.2 uniquement.
Sans domaine, la stack fonctionne quand même : j’obtiens un endpoint DNS ALB en HTTP uniquement. Pratique pour les environnements de staging.
CI/CD sans credentials long-lived
L’approche classique pour GitLab CI → AWS consiste à créer un utilisateur IAM, générer des access keys et les stocker dans les variables CI. Ça marche, mais vous vous retrouvez avec des credentials statiques qui n’expirent jamais et sont stockés dans les paramètres GitLab pour toujours.
La meilleure approche : la fédération OIDC. GitLab génère un JWT signé pour chaque exécution de pipeline. AWS vérifie le JWT auprès du provider OIDC de GitLab et émet des credentials temporaires. Aucune clé statique nulle part.
resource "aws_iam_openid_connect_provider" "gitlab" {
url = var.gitlab_url
client_id_list = [var.gitlab_url]
thumbprint_list = [var.gitlab_oidc_thumbprint]
}
resource "aws_iam_role" "gitlab_ci" {
name = "${local.prefix}-gitlab-ci"
assume_role_policy = data.aws_iam_policy_document.gitlab_ci_assume.json
max_session_duration = 3600
}La trust policy restreint quels pipelines peuvent assumer le rôle : uniquement la branche main et les tags du projet spécifique :
condition {
test = "StringLike"
variable = "<votre-gitlab-host>:sub"
values = [
"project_path:<votre-groupe>/<votre-projet>:ref_type:branch:ref:main",
"project_path:<votre-groupe>/<votre-projet>:ref_type:tag:ref:*",
]
}Dans .gitlab-ci.yml, le job demande un token OIDC et l’échange contre des credentials AWS :
deploy:
id_tokens:
AWS_OIDC_TOKEN:
aud: https://<votre-gitlab-host>
script:
- >
export $(aws sts assume-role-with-web-identity
--role-arn $OIDC_ROLE_ARN
--web-identity-token $AWS_OIDC_TOKEN
--role-session-name gitlab-ci
--query 'Credentials.[AccessKeyId,SecretAccessKey,SessionToken]'
--output text | awk '{print "AWS_ACCESS_KEY_ID="$1"\nAWS_SECRET_ACCESS_KEY="$2"\nAWS_SESSION_TOKEN="$3}')
- docker build -t $ECR_BACKEND_IMAGE .
- docker push $ECR_BACKEND_IMAGE
- aws ssm send-command --instance-ids $INSTANCE_ID --document-name AWS-RunShellScript --parameters 'commands=["cd /app && docker compose pull && docker compose up -d"]'Le rôle CI a uniquement la permission de pusher vers ECR et de déclencher des commandes SSM sur l’instance EC2. Rien d’autre.
Ce que je referais différemment
ECS Fargate pour les conteneurs applicatifs, EC2 pour Qdrant. Les conteneurs applicatifs (backend, frontend) sont stateless : ils sont parfaits pour Fargate. La seule raison pour laquelle j’ai tout gardé sur EC2, c’était la simplicité opérationnelle au départ. Avec Fargate pour l’app et une instance EC2 dédiée pour Qdrant, on obtient des déploiements rolling et une meilleure isolation des pannes.
RDS PostgreSQL plutôt que SQLite pour les métadonnées. SQLite fonctionne bien pour une instance unique, mais crée des problèmes dès qu’on veut scaler horizontalement ou faire du blue/green deployment. Le coût de migration est faible ; le gain en flexibilité future est élevé.
Mettre en place les alarmes CloudWatch dès le premier jour. J’ai ajouté le monitoring après le premier incident en production. L’alarme sur le compteur d’hôtes unhealthy de l’ALB devrait être la première chose qu’on crée, pas la dernière.
Conclusion
Choisir EC2 plutôt que Bedrock n’était pas idéologique. C’était une réponse pragmatique à trois contraintes : Qdrant comme store vectoriel, un binaire Rust compilé, et la prédictibilité des coûts pour une charge d’indexation variable.
L’infrastructure Terraform décrite ici (environ 500 lignes réparties sur huit fichiers) provisionne un déploiement production avec TLS, sauvegardes quotidiennes, CI/CD sans credentials, et stockage persistant protégé. Ce n’est pas le setup le plus simple, mais chaque élément justifie sa présence.
Si vous faites tourner une application AI self-hosted avec des contraintes similaires, le pattern EC2 + EBS + Secrets Manager vaut le coup d’être considéré. La charge opérationnelle est réelle, mais le contrôle et le profil de coût le justifient souvent.
Le template Terraform complet de cet article, généralisé et prêt à forker, est disponible sur github.com/Strawbang/terraform-aws-ai-stack.